Containerization-and-infrastructure-as-code
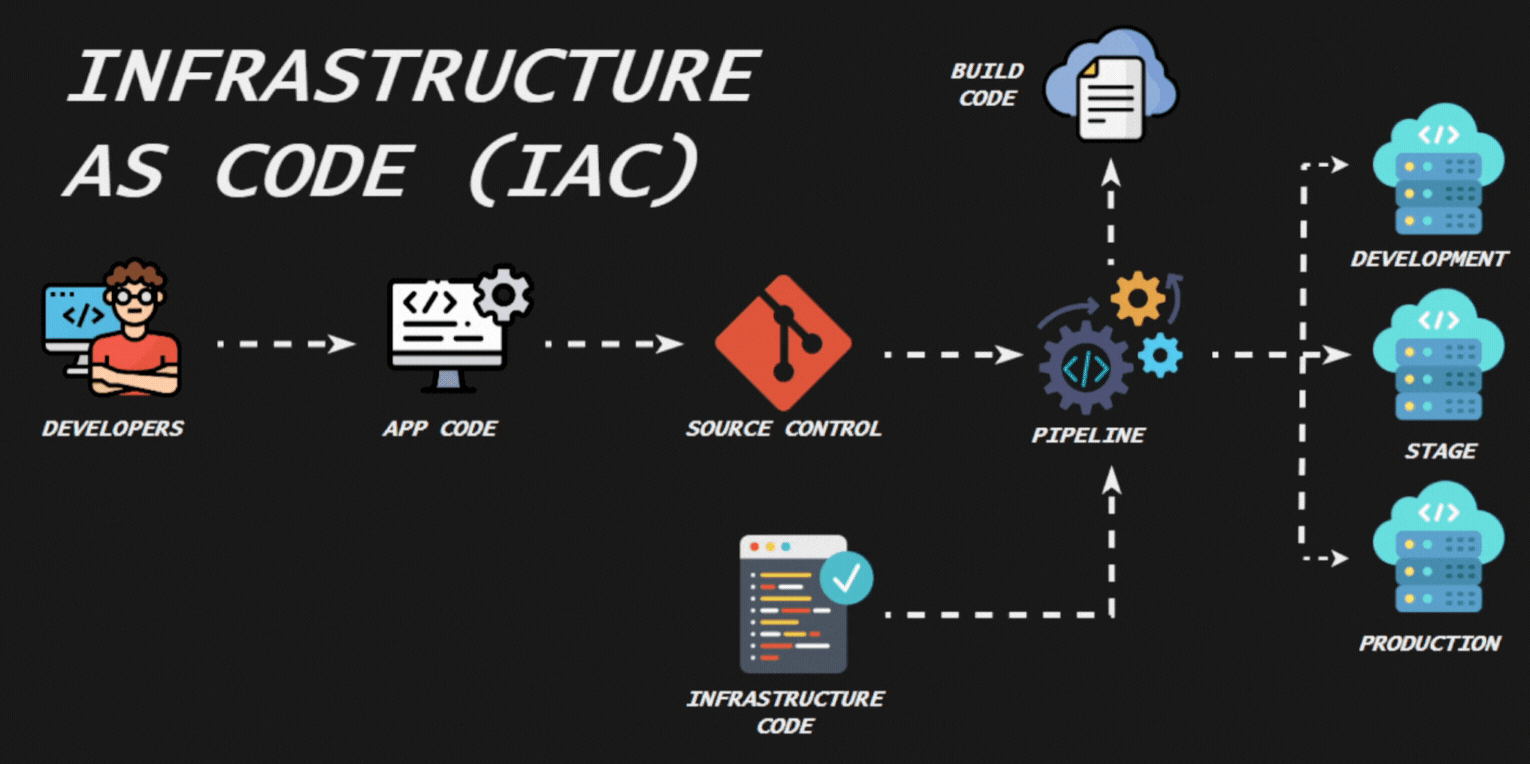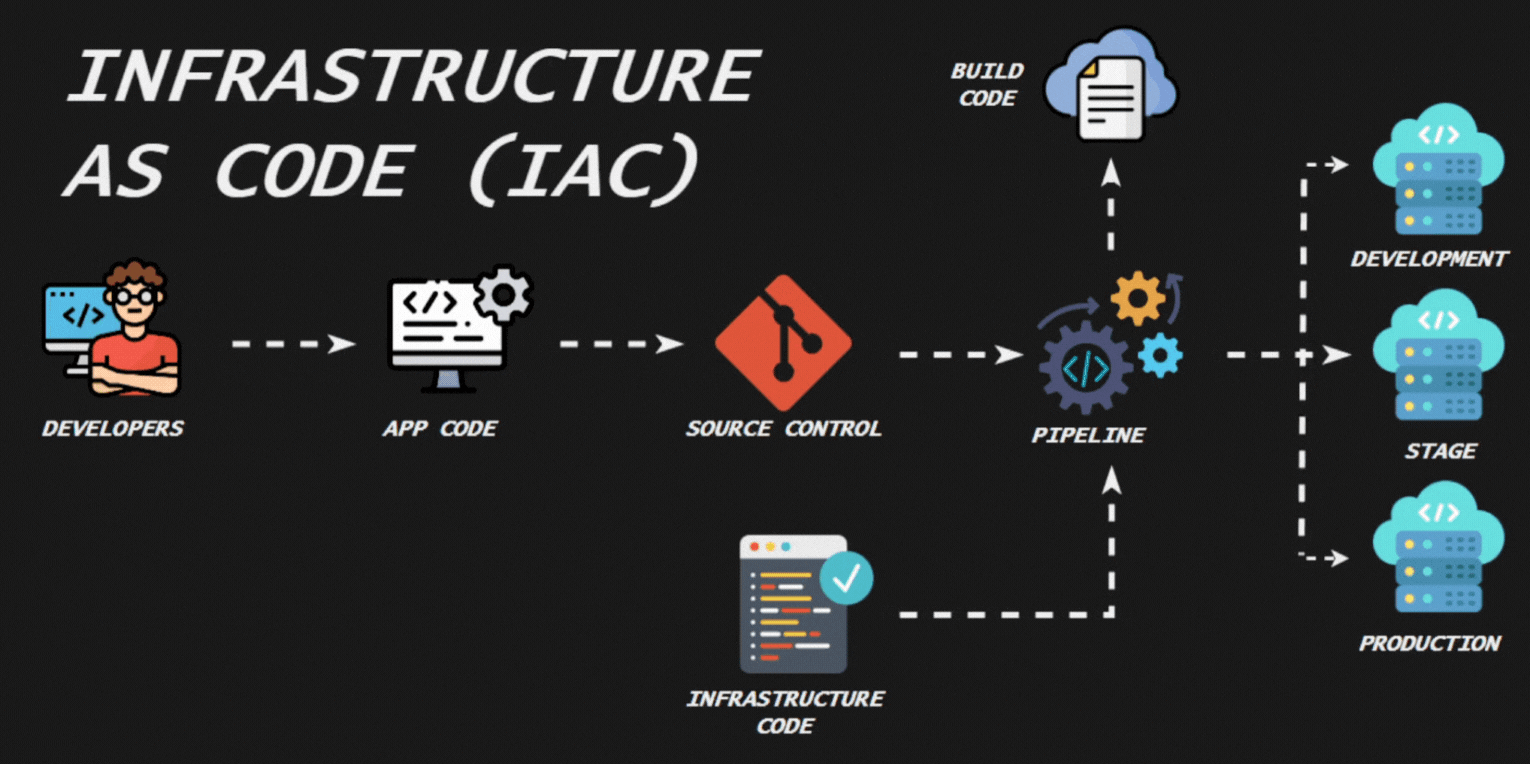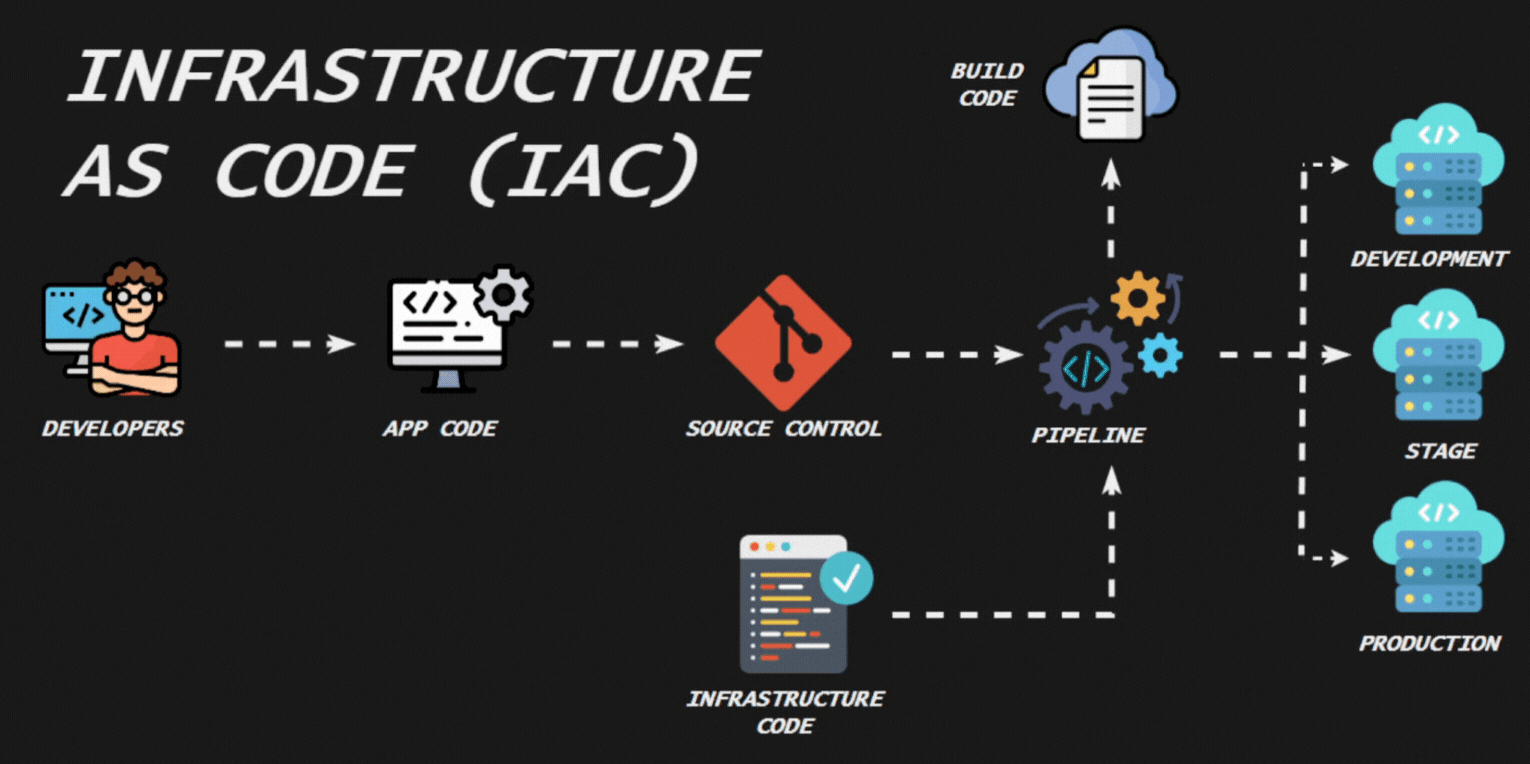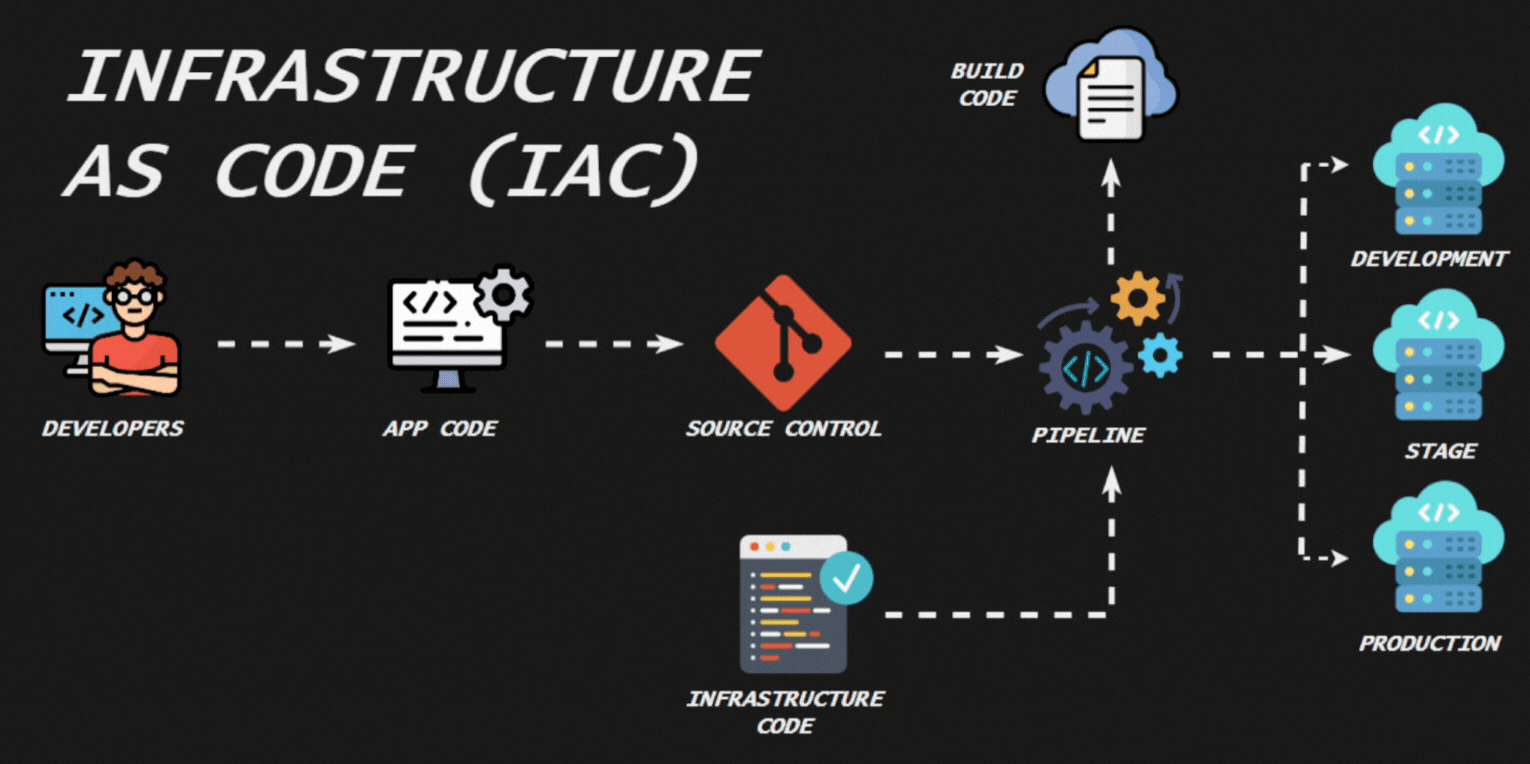
La contenerización es una tecnología que permite empaquetar una aplicación y todas sus dependencias (bibliotecas, archivos de configuración, etc.) en un contenedor. Esto asegura que la aplicación se ejecutará de manera consistente sin importar dónde se despliegue. Los contenedores son ligeros y aislados, lo que facilita la portabilidad, escalabilidad y gestión de aplicaciones.
Principales características de la contenerización:
- Aislamiento: Cada contenedor funciona de manera independiente y aislada del sistema operativo y otros contenedores.
- Portabilidad: Los contenedores pueden ejecutarse en cualquier entorno que soporte la tecnología de contenedores, como Docker.
- Ligereza: Los contenedores comparten el núcleo del sistema operativo y tienen un tamaño mucho menor en comparación con las máquinas virtuales.
- Consistencia: Garantiza que las aplicaciones se ejecuten de la misma manera en diferentes entornos, eliminando problemas de "funciona en mi máquina".
Tecnologías populares: Docker, Kubernetes.
Infraestructura como Código (IaC)
La Infraestructura como Código (IaC) es una práctica en la que la infraestructura de TI se gestiona y aprovisiona mediante archivos de configuración legibles por humanos y por máquinas, en lugar de configuraciones manuales o herramientas de administración interactivas. Esta práctica permite que la infraestructura se trate de manera similar al código de software, aplicando principios de desarrollo como control de versiones, pruebas y despliegue continuo.
Principales características de IaC:
- Automatización: Permite automatizar la configuración y gestión de la infraestructura.
- Reproducibilidad: Las configuraciones pueden ser versionadas, asegurando que las mismas configuraciones se puedan aplicar repetidamente con los mismos resultados.
- Escalabilidad: Facilita la escalabilidad de la infraestructura, ya que las configuraciones pueden ser replicadas en múltiples entornos.
- Documentación: El propio código actúa como documentación de la infraestructura, facilitando la comprensión y el mantenimiento.
- Control de versiones: Permite realizar un seguimiento de los cambios en la infraestructura, facilitando el rollback en caso de errores.
Herramientas populares: Terraform, Ansible, Chef, Puppet.
La contenerización y la Infraestructura como Código son prácticas modernas que mejoran la gestión, escalabilidad y portabilidad de aplicaciones e infraestructuras, alineándose con los principios de DevOps y facilitando la implementación de entornos consistentes y reproducibles.
Contenerización en Ingeniería de Datos

En el contexto de la ingeniería de datos, tanto la contenerización como la Infraestructura como Código (IaC) juegan roles cruciales para mejorar la eficiencia, escalabilidad y confiabilidad en la gestión y procesamiento de datos. A continuación se detalla cómo se aplican y ayudan estas tecnologías en la ingeniería de datos:
Beneficios y Aplicaciones:
-
Portabilidad y Consistencia: Los contenedores permiten que las aplicaciones de procesamiento de datos, como ETL (Extracción, Transformación y Carga), se ejecuten de manera consistente en diferentes entornos (desarrollo, pruebas, producción). Esto es esencial para asegurar que los pipelines de datos funcionen de la misma manera en todos los entornos.
-
Escalabilidad: Las tecnologías de orquestación de contenedores, como Kubernetes, facilitan la escalabilidad horizontal de los pipelines de datos. Esto significa que se pueden agregar más contenedores para manejar cargas de trabajo crecientes sin interrumpir el servicio.
-
Aislamiento de Dependencias: Cada pipeline de datos puede tener sus propias dependencias y configuraciones específicas. Los contenedores permiten aislar estas dependencias, evitando conflictos entre diferentes procesos de datos.
-
Fácil Despliegue y Gestión: Con herramientas como Docker, los equipos de datos pueden empaquetar sus aplicaciones y dependencias en contenedores, facilitando el despliegue y la gestión de los pipelines de datos en cualquier entorno.
Ejemplos de Uso:
- Ejecutar trabajos de ETL en contenedores Docker.
- Implementar clústeres de procesamiento de datos con Kubernetes.
- Desplegar y escalar aplicaciones de análisis de datos y machine learning.
Infraestructura como Código (IaC) en Ingeniería de Datos
Beneficios y Aplicaciones:
-
Automatización del Despliegue: IaC permite automatizar el aprovisionamiento y configuración de la infraestructura necesaria para los pipelines de datos, como servidores, bases de datos, redes, y otros recursos en la nube. Esto reduce el tiempo y el esfuerzo necesarios para configurar entornos complejos.
-
Reproducibilidad y Consistencia: Con IaC, se puede asegurar que la infraestructura de datos sea consistente y reproducible en diferentes entornos. Esto es crucial para mantener la integridad de los datos y la confiabilidad de los procesos de datos.
-
Control de Versiones y Auditoría: Los scripts de IaC se pueden versionar utilizando sistemas de control de versiones como Git. Esto permite rastrear cambios en la infraestructura y revertir a versiones anteriores en caso de problemas.
-
Facilidad de Escalabilidad: IaC facilita la escalabilidad de la infraestructura de datos. Por ejemplo, se pueden ajustar automáticamente los recursos en la nube en respuesta a cambios en la carga de trabajo.
Ejemplos de Uso:
- Usar Terraform para aprovisionar y gestionar clústeres de procesamiento de datos en la nube (como Amazon EMR, Google Dataproc).
- Configurar y gestionar bases de datos con scripts de Ansible.
- Desplegar y escalar servicios de datos en la nube utilizando CloudFormation o Azure Resource Manager.
Caso de Uso Integrado
Imagina un escenario donde una empresa necesita procesar grandes volúmenes de datos provenientes de múltiples fuentes (logs, bases de datos, APIs) para generar análisis en tiempo real y reportes diarios.
-
Contenerización:
- Los ingenieros de datos desarrollan un pipeline de ETL que extrae datos, los transforma y carga en un data warehouse.
- Este pipeline se empaqueta en un contenedor Docker, asegurando que todas las dependencias estén incluidas y que funcione de manera consistente en diferentes entornos.
-
Infraestructura como Código:
- Usan Terraform para aprovisionar clústeres de procesamiento de datos en AWS, incluyendo instancias EC2, bases de datos RDS y servicios de almacenamiento S3.
- Ansible se utiliza para configurar las instancias y asegurar que todas las dependencias necesarias para los contenedores de datos estén presentes.
- Los scripts de IaC son versionados y almacenados en un repositorio Git, permitiendo revisiones de código y auditoría de cambios.
-
Orquestación y Despliegue:
- Kubernetes se emplea para orquestar los contenedores de ETL, gestionando la escalabilidad y la alta disponibilidad del pipeline de datos.
- Jenkins o una herramienta similar se utiliza para implementar pipelines de CI/CD que automatizan el despliegue y la actualización de los contenedores de ETL.
Al combinar la contenerización y IaC, la empresa puede gestionar eficientemente su infraestructura de datos, asegurando que los pipelines sean robustos, escalables y fáciles de gestionar y desplegar.